This morning I finished listening to Episode 5 of Data Stories: How To Learn Data Visualization. Data Stories is a bi-weekly podcast on data visualisation produced by Enrico Bertini and Moritz Stefaner, episode 5 also featuring Andy Kirk. For anyone interested in Data Visualisation I’d highly recommend you give it a listen.
Like many others I’m at the beginning of my data visualisation journey, one of the things this episode highlighted was there is a whole world of data visualisation experts out there that I’ve yet to start stealing learning from. Fortunately today another Visualisation expert, Nathan Yau (FlowingData), posted his list of Data and visualization blogs worth following. Perfect!
I could’ve gone through the list and individually subscribed to each of the blogs feeds but I’m lazy (so lazy that a 15 minute hack has turned into a 3 hour write-up <sigh>) and just wanted to dump them into my Google Reader. This is a problem Tony Hirst has encountered in Feed-detection From Blog URL Lists, with OPML Output. One thing that is not clear is how Tony got his two column CSV of source urls. There are various tools Tony could have used to do this. Here’s my take on converting a page of blog urls into an OPML bundle.
Step 1 Extracting blogs urls: Method 1 using Scraper Chrome Extension
“Scraper is a Google Chrome extension for getting data out of web pages and into spreadsheets.”
Chrome users can grab a copy of Scraper here. Once installed if you go to Nathan Yan’s Data and visualization blogs worth following and right-click on the first link in the list and select ‘Scrape similar’


In this example Scraper should default to ‘//div[1]/div[2]/ul[1]/li/a’. Here’s a quick explanation of how I read this query. Because it starts with // it will select “nodes in the document from the current node that match the selection no matter where they are” for me this is the trigger to read the query from right to left as we are matching an endpoint pattern. So:
match all <a> in all <li> in first <ul> of second <div> (<div class=”entry-content”> of first <div> (<div class=”entry”>)
this give use the links from the first block of bullet point. We want the links from all of the bullet points lists so the pattern we want is
match first <a> in all <li> in all <ul> of second <div> of first <div>
So basically we need to switch a to a[1] and ul[1] to ul e.g. ‘//div[1]/div[2]/ul/li/a[1]’. Edit the XPath query and in the columns section beneath change the order by clicking and dragging so that @href/URL comes first. Clicking on the ‘Scrape’ button to get a new preview which should now contain a list of 37 urls. Click on Export to Google Docs … You are now ready to move to Step 2 Auto-discovering feed urls below.
Step 1 Extracting blogs urls: Method 2 using Google Spreadsheet importXML function
Another way to get this data is to directly scrape it using Google Spreadsheets using the importXML function. This function also uses XPath to extract parts of a webpage so we can reuse the query used in Method 1 but get the data straight into a spreadsheet (it’s also a live link so if Nathan adds a new link the spreadsheet will automatically update to include this). Let give it a go.
Create a new spreadsheet and in cells A1 to B3 enter the column heading Link, Title and Url. Next in cell A2 enter:
=ImportXML(“http://flowingdata.com/2012/04/27/data-and-visualization-blogs-worth-following/”,”//div[1]/div[2]/ul/li/a[1]/@href”)
Note the addition of @href. This is included to extract the href attribute in the <a>. You should now have similar list of 37 urls from Nathan’s post. To get titles we could enter another importXML function in cell B2 using the XPath ‘//div[1]/div[2]/ul/li/a[1]’ which will extract the text between <a></a>. Another way is to actual scrape the data from the target url. So in cell B2 enter:
=ImportXML(A2,”//title”)
So this will go to the url in A2 (http://infosthetics.com/) and extract anything wrapped in <title>
Now select cell B2 and fill the column down to get titles for all the urls. Finally we need to select the entire B column and Copy/Paste values only. The reason we do this is Google Spreadsheets only allows 50 importXML function per spreadsheet and we’ll need 37 more to get the RSS feeds for these sites.

Step 2 Auto-discovering feed urls
Initially i tried using Feed Autodiscovery With YQL with importXML using an XPath of “//link/@href” but I was not getting any results. So instead decided to auto-detect the feed directly using importXML. In cell C2 enter:
=ImportXML(A2,”/html/head/link[@rel=’alternate’][1]/@href”)
This time the XPath starts at the XML tree root (<html>) looks in the <head> for the first link with the attribute rel=’alternative’. From Tony’s post:
Remember, feed autodiscovery relies on web page containing the following construction in the HTML <head>element:
<link rel=”alternate” type=”application/rss+xml” href=”FEED_URL” title=”FEED_NAME” />
[I tried using //link[@rel=”alternate” and @type=”application/rss+xml”] but Google Spreadsheet didn’t like it, instead grabbing the first rel=alternate link]
Fill cell C2 down the rest of the column to get RSS feeds for the other urls. You’ll notice that there’s a #N/A for http://neoformix.com/ this is because their feed isn’t auto-discoverable. Visiting their site there is a XML link (http://neoformix.com/index.xml) that we can just paste into our spreadsheet (tiding data is a usual processes in data visualisation).
Step 3 Generating an OPML bundle

OPML File of Nathan Yau’s recommended Data and Visualisation Blogs
And because I’ve imported these into Google Reader here’s an aggregated page of their posts.
Update:
Tony Hirst said:
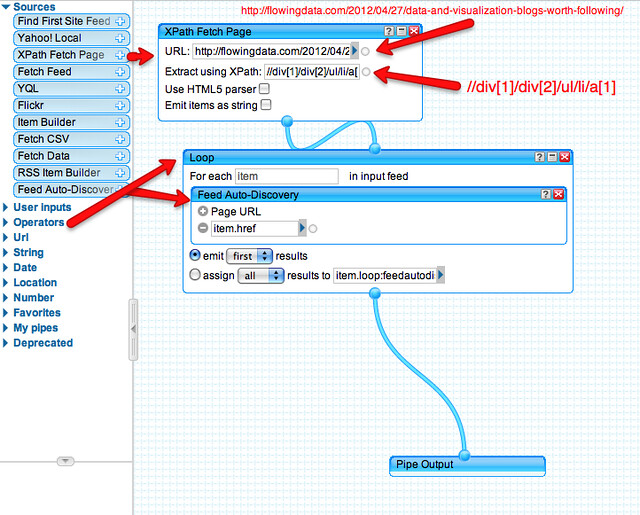
@mhawksey there’s also the new Yahoo pipes XPath Fetch block… bit.ly/JEJtLz
— Tony Hirst (@psychemedia) April 27, 2012
@mhawksey so for example: list of feed URLs bit.ly/Jr51dj
— Tony Hirst (@psychemedia) April 27, 2012
I said:
@psychemedia :`s
— Martin Hawksey (@mhawksey) April 27, 2012
and the how to
CFHE12 Week 2 Analysis: Data! Show me your data and I’ll show you mine JISC CETIS MASHe
[…] as blogs are added or removed from the Participant Feeds page). For more details on this recipe see Generating an OPML RSS bundle from a page of links using Google Spreadsheets for more […]
Registering blog addresses and generating a OPML file (Notes on FeedWordPress and MOOC-In-a-Box) JISC CETIS MASHe
[…] response was to direct Martin to http://opml-generator.appspot.com/ which I used in Generating an OPML RSS bundle from a page of links using Google Spreadsheets. This takes a Google Spreadsheet of RSS feeds and generates an OPML bundle. Part of this solution […]