In my last post on Canvas Network Discussion Activity Data I mentioned I was a little disappointed to not be able to use social network analysis (SNA) modelling techniques on the Canvas Network discussion boards. My main barrier was accessing the data via the Canvas API using my preferred toolset. Fortunately Brian Whitmer at instructure.com (the company behind Canvas) posted a comment highlighting that as a student on the course it was easy for me to get access to this data using a token generated on my Canvas profile page. With this new information in this post I’ll cover three main areas:
- a very quick introduction into techniques/opportunities for analysing threaded networks using SNA;
- how I retrieved data from the Canvas platform for the #LAK13 discussions; and finally
- some analysis using the NodeXL add-on for Microsoft Excel (Windows).
On Friday 1st March at 4pm GMT I’ll also be having a live Hangout on Air with Marc Smith, one of the original creators and continued project coordinator of NodeXL. The live feed will be embedded below embedded here and you can ask question via Twitter or Google+ using the combined hashtags #lak13 and #nodexl e.g. ‘What the best place to find out more about NodeXL? #lak13 #nodexl’. For the hangout session we’ll look at how easy it is to use NodeXL to analyse a Twitter hashtag community in a couple of clicks. [The rest of this post is introducing a more advanced use of NodeXL so if I lose you in the rest of this post fear not as the session will be a lot easier going]
Opportunities for analysing threaded networks using SNA
Hello graph



There is a lot more to understand about these types of graphs, but this basic concept means I know if I have any relationship data its easy to graph and explore.
Hello SNAPP
At this point it’s worth mentioning the browser plugin SNAPP.
The Social Networks Adapting Pedagogical Practice (SNAPP) tool performs real-time social network analysis and visualization of discussion forum activity within popular commercial and open source Learning Management Systems (LMS). SNAPP essentially serves as a diagnostic instrument, allowing teaching staff to evaluate student behavioural patterns against learning activity design objectives and intervene as required a timely manner.
Valuable interaction data is stored within a discussion forum but from the default threaded display of messages it is difficult to determine the level and direction of activity between participants. SNAPP infers relationship ties from the post-reply data and renders a social network diagram below the forum thread. The social network visualization can be filtered based upon user activity and social network data can be exported for further analysis in NetDraw. SNAPP integrates seamlessly with a variety of Learning Management Systems (Blackboard, Moodle and Desire2Learn) and must be triggered while a forum thread is displayed in a Web browser.
The social network diagrams can be used to identify:
- isolated students
- facilitator-centric network patterns where a tutor or academic is central to the network with little interaction occurring between student participants
- group malfunction
- users that bridge smaller clustered networks and serve as information brokers
The paper referencing SNA research supporting these areas was presented at LAK11 (if you don’t have access also available in the presentation’s slidedeck). The paper Visualizing Threaded Conversation Networks: Mining Message Boards and Email Lists for Actionable Insights (Hansen, Shneiderman & Smith, 2010) also highlights simple ways to identify question people, answer people and discussion starters which are all potentially very useful within courses for identifying network clusters individuals might want to join/follow.
Retrieving data from Canvas
Hopefully with that quick intro you can see there might be some value in using SNA from threaded discussion analysis. Reading the SNAPP overview hopefully you spotted that it currently doesn’t support extracting data from Canvas discussion boards. This is an opportunity to understand some of the analysis SNAPP is doing behind the scenes.
Hello Google Apps Script
If you have been following my posts you’ll see that I favour using Google Apps Script as a lightweight tool for extracting data. Thanks to Brian (Instructure) I’ve got a way to access the Discussion Topics API. Looking at the API documents I decided the best way to proceed was to get all of the LAK13 discussion topics (top level information) and use this to get the full topic data. If you speak JSON we are essentially turning this:

into this:

finally getting this (web version here):

The code to do this is available here. I’m going to spare you the details of the code but here are the instructions is you’d like to export data from other Canvas hosted discussion boards. If you’re not interested in that you can just jump to the next section.
Generating an edge list (extracting data) from Canvas to Google Sheets
- Create a new Google Spreadsheet and then in Tool > Script editor copy in the code from here
- If you are not pulling data from LAK13 you need to edit values in lines 2-4. If you visit your course homepage hopefully you can decode the url pattern based on the example for LAK13 https://learn.canvas.net/courses/33 (I should also point out you need to be enrolled on the course to receive data. Also read Canvas API Policy)
- Next you need an access token which is generated from your Canvas Profile Settings page. Scroll down to the bottom and click New Access Token, filling in a purpose and leaving expires blank. Make a copy of the token as it’s needed for the next step (I added a copy to a .txt file just in case the next step didn’t work
- Back in the Script Editor in Google Spreadsheets click File > Project Properties. In the ‘Project properties’ tab click ‘+ Add row’ and replace (name) with access_token and (value) with the token you got from Canvas before clicking Save

- Make sure everything is saved in the Script Editor and then Run > getCanvasDiscussionEdges, wait for the script to finish and on Sheet1 you should have a bunch of data to play with.

Using NodeXL to analyse Canvas Discussions
There are a number of different questions we could ask of the LAK13 data. The particular one I want to look at is who are the core community members stimulating/facilitating discussion (e.g. applying a connectivist theory who are the people you might want to connect with). To do this we need to (I’m assuming you’ve already installed NodeXL):
- Download the data extracted to the Google Spreadsheet (File > Download as > Microsoft Excel). [If you just want the data I’ve extracted here’s the download link – the data is automatically refreshed nightly]
- Open the download file in Excel and in the created_at column select all and Format Cells as General (I needed to do this because NodeXL was miss formating dates on import)
- Start a new NodeXL Template (I use the NodeXL Excel Template option from my windows Start menu)
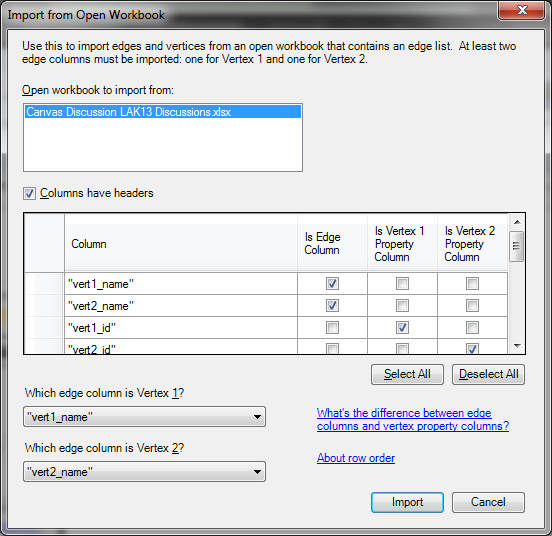
- From the NodeXL ribbon you want to Import > From Open Workbook

- In the import dialog vert1_name and vert2_name are edges, anything else prefixed with ‘vert’ is assigned to the corresponding Vertex n property column and everything else is an Vertex 1 property:

- Once imported you can open the Edges sheet, select the created_at column and Format Cells reassigns a date/time format.
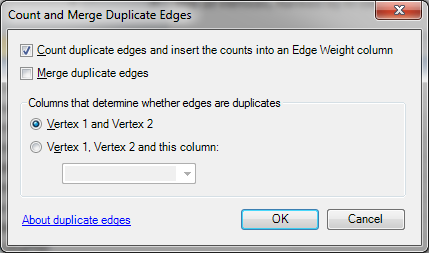
- In Prepare Data chose ‘Count and merge duplicate edges’ and select Count and Vertex1 and Vertex 2

- In the Graph section of the NodeXL ribbon we want to make this a directed graph (replies are directed) and choose you layout algorithm (I usually go Harel-Koren Fast Multiscale)

- Next we want to prepare the data we want to analyse. In the Autofill Columns (within Visual Properties portion of the ribbon) set Edge Visibility to ‘topic_id’ and in Edge Visibility Options set ‘If the source column number is: Not equal to 558’ Show otherwise Skip (this will skip edges that are responses to the Pre-course discussion forum – I’ll let you question this decision in the comments/forum)

- Click Ok then Autofill
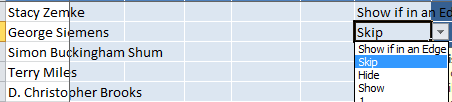
- Next open the Vertices sheet and select all the rows (Ctrl+A) and from the Visibility option select ‘Show if in an Edge’

- Now find the row in the Vertices sheet for George Siemens and Skip (doing this were creating a ‘what if George wasn’t there’ scenario

- Open the Graph Metrics window and add Vertex in-degree, vertex out-degree, Vertex betweenness and closeness centrality and Top items (in the Top items options you’ll need to add these as the metrics you want top 10s for), finally click Calculate metrics.





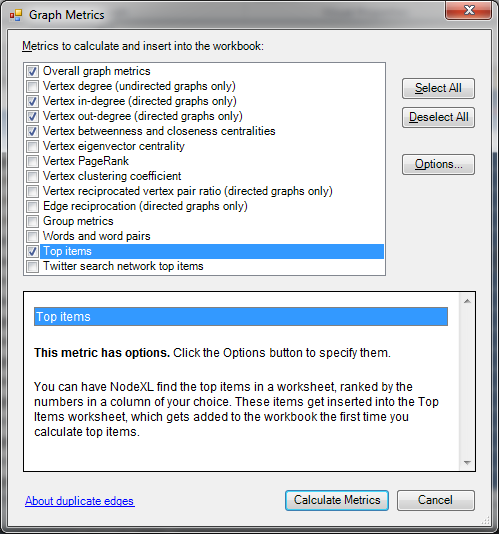
At this point you could use the calculated metrics to weight nodes in a graph, but for now I’m going to skip that. You should now have a Top Items sheet with some useful information. In the Betweenness Centrality list you should have these names:
- Martin Hawksey
- Simon Knight
- Alex Perrier
- Khaldoon Dhou
- Rosa Estriégana Valdehita
- Maha Al-Freih
- Suzanne Shaffer
- Maxim Skryabin
- Bryan Braul
- Peter Robertso
Excluding the pre-course discussion forum and George Siemens the discussions these people have engaged with provide the shortest paths to other people engaging in discussions on the Canvas site. Strategically these are potentially useful people within the network that you might want to follow, question or engage with.
Getting to this point obliviously hasn’t been straight forward and had SNAPP been available in this instance it would have turned this in to a far shorter post. Programmatically using tools like R we could have arrived at the same answer with a couple of lines of code (that might be my challenge for next week ;). What it has hopefully illustrated is if you have data in an edge format (two column relationships) tools like NodeXL make it possible for you use SNA modelling techniques to gain insight. (I’m sure it also illustrates that data wrangling isn’t always straight forward, but guess what that’s life).

