Last month I posted Free the tweets! Export TwapperKeeper archives using Google Spreadsheet, which was a response to the announcement that TwapperKeeper would be removing public access to archives on the 6th January. This solution was limited to archives smaller than 15,000 tweets (although minor tweaking could probably get more). Since then Tony Hirst has come up with a couple of other solutions:
- Rescuing Twapperkeeper Archives Before They Vanish « OUseful.Info
- Rescuing Twapperkeeper Archives Before They Vanish, Redux « OUseful.Info
- Python Script for Exporting (Large) Twapperkeeper Archives By User « OUseful.Info
One of the limits these solutions have is they only collect the data stored on TwapperKeeper missing lots of other juicy data like in_reply_to, location, retweet_count (here’s what a tweet used to look like, now there is more data). Whilst this data is probably of little interest to most people for people like me it opens the opportunity to do other interesting stuff. So here’s a way you can make a copy of a Twapper Keeper archive and rebuild the data using Google Refine.
- You’re going to need a copy of Google Refine and install/run it
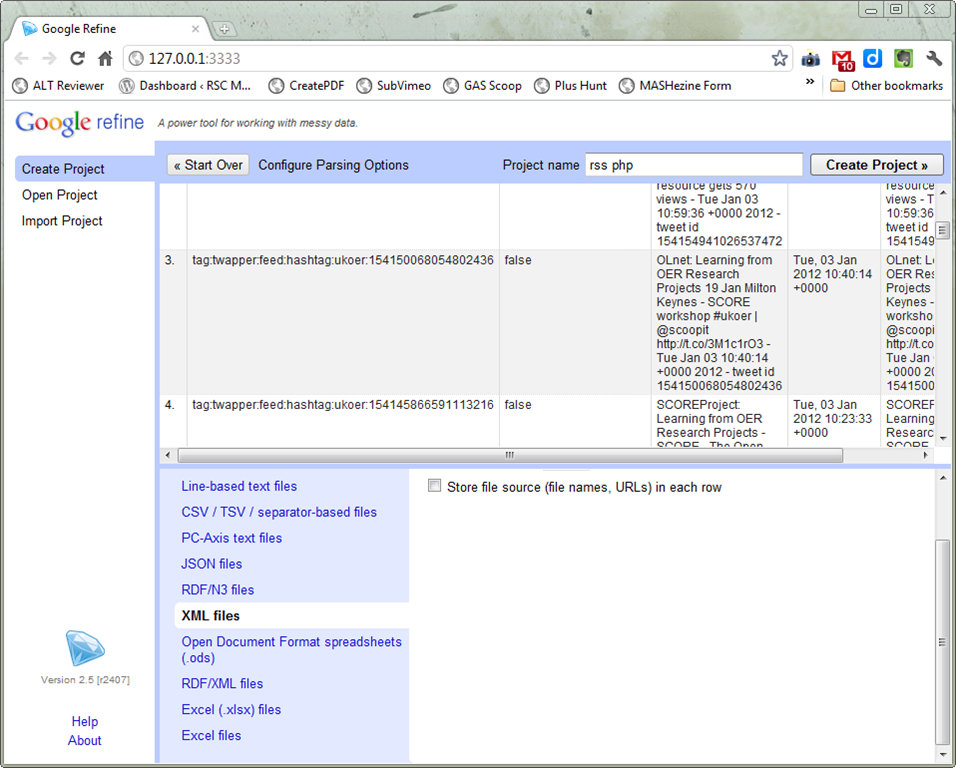
- Visit the Twapper Keeper page of the archive you want. On the page copy the RSS Permalink into the URL box in Google Refine adding &l=50000 to the end e.g. the ukoer archive is http://twapperkeeper.com/rss.php?type=hashtag&name=ukoer&l=50000 and click Next.
- In the preview window that appears switch ‘Parse data as’ to XML files. Scroll the top pane down to hover over the ‘item’ tag and click

- You should now have a preview with the data split in columns. Enter a Project name and click ‘Create Project’

- From the ‘item – title’ column dropdown select Edit column > Add column based on this column…
- In the dialog that opens enter a New column name ‘id_str’ and the Expression
smartSplit(value," ")[-1](this splits the cell and returns the last group of text) - From the new id_str column dropdown select Edit column > Add column by fetching URLs… and enter a name ‘meta’, change throttle delay to 500 and enter the expression
"https://api.twitter.com/1/statuses/show.json?id="+value+"&include_entities=true"(that’s with quotes), then click OK. [What we’ve done is extract a tweet id and then asked refine to fetch details about it from the Twitter API] - Wait a bit (it took about 4 hours to get data from 8,000 tweets)

Once you have the raw data you can use Refine to make new columns using the expression parseJson(value) then navigate the object namespace. You might find it useful to paste a cell value into http://jsonviewer.stack.hu/ to see the structure. So to make a column which extracts the tweets full name you’d use parseJson(value).user.name
So don’t delay ‘free the tweets’